
Overloading vs Overriding (test article)
If you omit or remove the virtual keyword from the base class definition, the method in the derived class will no longer be considered an override, but a completely new method declared on that derived class. This is because, in C++, the virtual keyword indicates that a function is intended to be overriden in a derived class to facilitate polymorphism.
class Vehicle {
public:
Vehicle(std::string brand, std::string color, int weight, int year);
void drive();
int details(std::string);
protected:
std::string brand;
std::string color;
int weight;
int year;
};
In this example above, the details is just a regular method of the base class. When you define another details method in the derived class with a different return type, it does not override the base class one, it just hides it. Now the base class and derived class methods are two completely independent methods. The derived class will just simply shadow the base class method.
If you have these two classes:
class Animal
{
public:
void eat() { std::cout << "I'm eating generic food."; }
};
class Cat : public Animal
{
public:
void eat() { std::cout << "I'm eating a rat."; }
};
In our main function:
Animal *animal = new Animal;
Cat *cat = new Cat;
animal->eat(); // Outputs: "I'm eating generic food."
cat->eat(); // Outputs: "I'm eating a rat."
So far so good, right? Animals eat generic food, cats eat rats, all without virtual.
Let’s change it a little now so that eat() is called via an intermediate function (a trivial function just for this example):
// This can go at the top of the main.cpp file
void func(Animal *xyz) { xyz->eat(); }
Now our main function is:
Animal *animal = new Animal;
Cat *cat = new Cat;
func(animal); // Outputs: "I'm eating generic food."
func(cat); // Outputs: "I'm eating generic food."
Uh oh… we passed a Cat into func(), but it won’t eat rats. Should you overload func() so it takes a Cat*? If you have to derive more animals from Animal they would all need their own func().
The solution is to make eat() from the Animal class a virtual function:
class Animal
{
public:
virtual void eat() { std::cout << "I'm eating generic food."; }
};
class Cat : public Animal
{
public:
void eat() { std::cout << "I'm eating a rat."; }
};
int main() {
Animal *rufus = new Cat();
rufus.eat(); // #static-dispatch (see below)
}
Key takeaway:
Virtual Functions are used to support runtime polymorphism.
That is, virtual keyword tells the compiler not to make the decision (of function binding) at compile time, rather postpone it for runtime".
The key point is that the virtual keyword enables polymorphic behavior, requiring the derived class to match the base class method signature exactly for overriding. Without virtual, the derived class method with the same name does not override but hides the base class method, and the derived class can change the return type.
Without virtual you get “static binding/dispatch”. Which implementation of the method is used gets decided at compile time based on the type of the pointer that you call through.
With virtual you get “dynamic binding/dispatch”. Which implementation of the method is used gets decided at run time based on the type of the pointed-to object, what it was originally constructed as.
Overloading
- you have two or more functions in the same scope having the same name, the function that better matches the arguments when a call is made wins
- as opposed to calling a virtual function, is that the function thats called is selected at compile time, because it all depends on the static type of the argument
Lets say we have an overload for B and one for D, and the argument is a reference to B, but it really points to a D object, then the overload for B is chosen in C++.
class B {
std::string hello() { return "Hello Earth!"; }
}
class D : public B {
std::string hello() { return "Hello Saturn!"; }
}
int main() {
B hello1 = new B();
B hello2 = new D();
hello1->hello(); // <-- prints "Hello Earth"
hello2->hello(); // <-- prints "Hello Saturn" (requires virtual keyword, so that the implementation of the method hello() will be looked up at runtime, what it will original get constructed as - else it just prints base class method)
}
This is called static dispatch #static-dispatch as opposed to dynamic dispatch. You overload if you want to do the same as another function having the same name, but you want to do that for another argument type.
Example:
void print(Foo const& f) {
// print a foo
}
void print(Bar const& b) {
// print a bar
}
Both print functions print their argument, therefore they are overloaded. But the first prints a Foo and the second prints a Bar. If you have two functions that do different things, its considered bad style when they have the same name - because it can lead to confusion about what will happen when you actually call the functions.
Another use case for overloading is when you have additional parameters for functions, but they just forward control to other functions.
Example:
void print(Foo & f, PrintAttributes b) {
/* ... */
}
void print(Foo & f, std::string const& header, bool printBold) {
print(f, PrintAttributes(header, printBold));
}
Overriding
Overriding a function is entirely different than overloading, and serves an entirely different purpose. Function overriding is how polymorphism works in C++. You override a function to change the behavior of that function in a derived class. In this way, a base class provides interface, and the derived class provides implementation.
- has nothing to do with overloading
- it means that if you have a virtual function in a base class, you can write a function with the same signature in the derived class and the function in the derived class overrides the function of the base class.
Example:
struct base {
virtual void print() { cout << "base!"; }
}
struct derived: base {
virtual void print() { cout << "derived!"; }
}
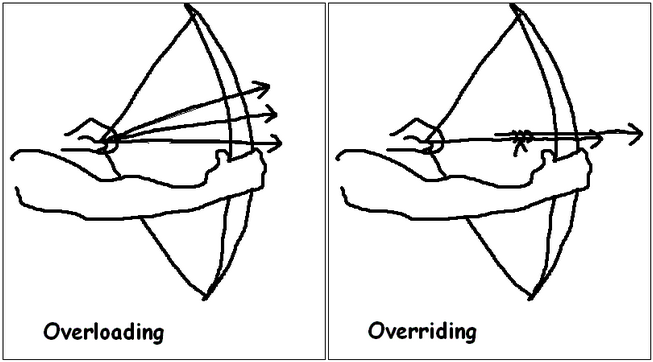
Use cases for overloading and overriding
We overload functions for three reasons
- To provide two (or more) functions that perform similar, closely related things, differentiated by the types and/or number of arguments it accepts.
void Log(std::string msg); // logs msg to stdout
void Log(std::string msg, std::ofstream) // logs msg to file
- To provide two (or more) ways to perform the same action
void Plot(Point p); // plots a point at (pt.x, pt.y)
void Plot(int x, int y); // plots a point at (x, y)
- To provide the ability to perform an equivalent action given two (or more) different input types
wchar_t ToUnicode(char c);
std::wstring ToUnicode(std::string s);
In some cases it’s worth arguing that a function of a different name is a better choice than an overloaded function. In the case of constructors, overloading is the only choice.
Overriding is useful when we inherit from a base class and wish to extend or modify its functionality. Even when the object is cast as the base class, it calls your overridden function, not the base one.
[INFO]: You can neither “override” nor “overload” variables - the right term is “shadowing”